grep模式匹配命令
“grep是一种强大的文本搜索工具。”
概述
grep全称Globally search a Regular Expression and Print是一种强大的文本搜索工具。它能使用正则表达式搜索文本,并把匹配的行打印出来。
grep的工作方式是在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。grep命令中允许指定的串语句是一个规则表达式,这是一种允许使用某些特殊键盘字符的指定字符串的方法,这种方法中的特殊键盘字符可以用于代表其他字符也可以进一步定义模式匹配工作方式。
基本操作
grep命令用于打印输出文本中匹配的模式串,它使用正则表达式作为模式匹配的条件。grep支持三种正则表达式引擎,分别用三个参数指定:
| 参数 | 说明 |
|---|---|
-E |
POSIX扩展正则表达式,ERE |
-G |
POSIX基本正则表达式,BRE |
-P |
Perl正则表达式,PCRE |
在没学过perl语言的大多数情况下你将只会使用到ERE和BRE。
先介绍一下grep命令的常用参数:
| 参数 | 说明 |
|---|---|
-b |
将二进制文件作为文本来进行匹配 |
-c |
统计以模式匹配的数目 |
-i |
忽略大小写 |
-n |
显示匹配文本所在行的行号 |
-v |
反选,输出不匹配行的内容 |
-r |
递归匹配查找 |
-A n |
n为正整数,表示after的意思,除了列出匹配行之外,还列出后面的n行 |
-B n |
n为正整数,表示before的意思,除了列出匹配行之外,还列出前面的n行 |
--color=auto |
将输出中的匹配项设置为自动颜色显示 |
注:在大多数发行版中是默认设置了grep的颜色的,你可以通过参数指定或修改GREP_COLOR环境变量。

使用正则表达式
使用基本正则表达式,BRE
- 位置
查找test文件中以wen开头的行
1 | grep 'wen' test |

- 数量
1 | # 将匹配以'h'开头以'o'结尾的所有字符串 |
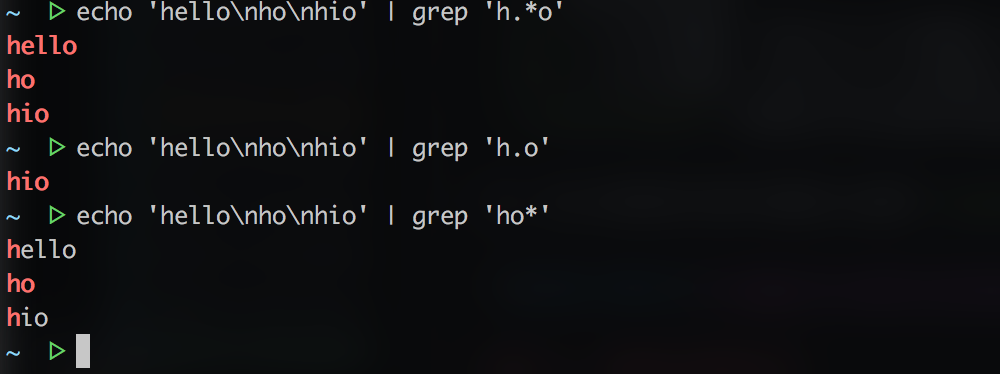
- 选择
1 |
|
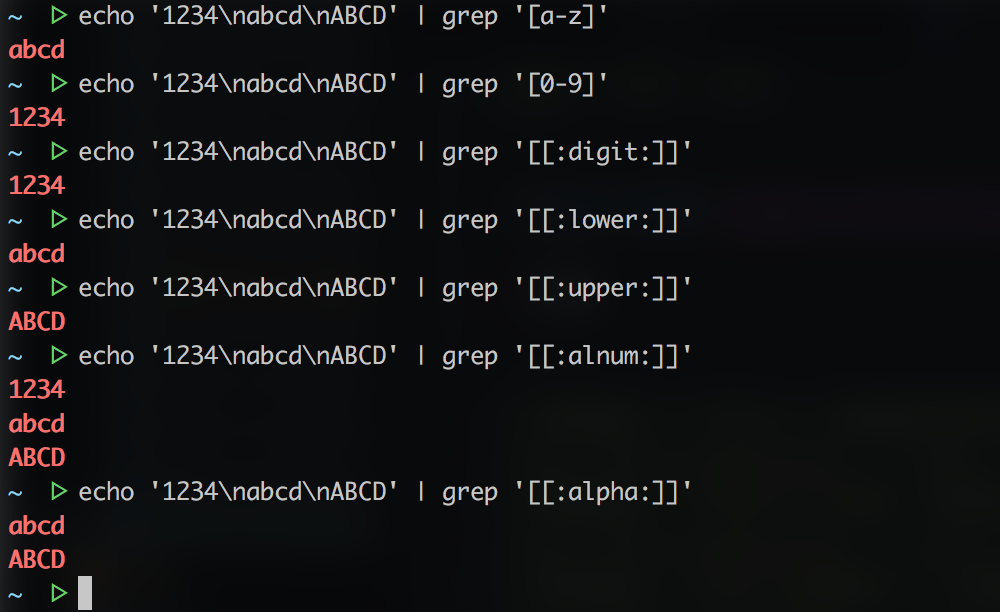
下面包含完整的特殊符号及说明:
| 特殊符号 | 说明 |
|---|---|
[:alnum:] |
代表英文大小写字节及数字,亦即 0-9, A-Z, a-z |
[:alpha:] |
代表任何英文大小写字节,亦即 A-Z, a-z |
[:blank:] |
代表空白键与 [Tab] 按键两者 |
[:cntrl:] |
代表键盘上面的控制按键,亦即包括 CR, LF, Tab, Del.. 等等 |
[:digit:] |
代表数字而已,亦即 0-9 |
[:graph:] |
除了空白字节 (空白键与 [Tab] 按键) 外的其他所有按键 |
[:lower:] |
代表小写字节,亦即 a-z |
[:print:] |
代表任何可以被列印出来的字节 |
[:punct:] |
代表标点符号 (punctuation symbol),亦即:” ‘ ? ! ; : # $… |
[:upper:] |
代表大写字节,亦即 A-Z |
[:space:] |
任何会产生空白的字节,包括空白键, [Tab], CR 等等 |
[:xdigit:] |
代表 16 进位的数字类型,因此包括: 0-9, A-F, a-f 的数字与字节 |
注意:之所以要使用特殊符号,是因为[a-z]不是在所有情况下都管用,这还与主机当前的语系有关,即设置在LANG环境变量的值,zh_CN.UTF-8的[a-z]即为所有小写字母,其它语系可能是大小写交替的如,a A b B...z Z,[a-z]中就可能包含大写字母。所以在使用[a-z]时请确保当前语系的影响,使用[:lower:]则不会有这个问题。
- 排除字符
1 | echo 'hello|aloha' | grep '[^o]' |

注意:当^放到中括号内为排除字符,否则表示行首。
使用扩展正则表达式,ERE
要通过grep使用扩展正则表达式需要加上-E参数,或使用egrep。
- 数量
1 | # 只匹配"zo" |
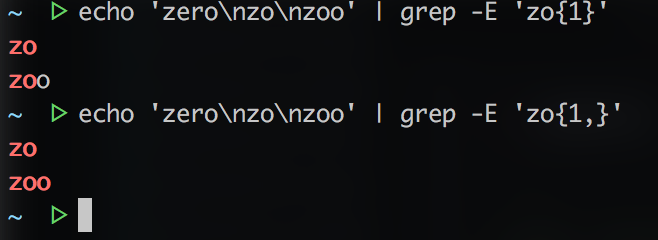
- 选择
1 | # 匹配"www.baidu.com"和"www.google.com" |

注意:因为.号有特殊含义,所以需要转义。