正则表达式基础
“工具和灵感,都是利器。当来自不同的领域,不同类型的创造者的工具和灵感互相碰撞的时候,才会迸发出更多的可能性。”
概述
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由UNIX中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有 regexp、regex,复数有regexps、regexes、regexen。
在做文字处理或编写程序时,用到查找、替换等功能,使用正则表达式能够简单快捷的完成目标。简单而言,正则表达式通过一些特殊符号的帮助,使用户可以轻松快捷的完成查找、删除、替换等处理程序。例如grep, expr, sed , awk或 vi 中经常会使用到正则表达式,为了充分发挥shell编程的威力,需要精通正则表达式。正规表示法基本上是一种『表示法』, 只要工具程序支持这种表示法,那么该工具程序就可以用来作为正规表示法的字符串处理之用。
基本语法
一个正则表达式通常被称为一个模式(pattern),为用来描述或者匹配一系列符合某个句法规则的字符串。
选择
|竖直分隔符表示选择,例如”boy|girl”可以匹配”boy”或者”girl”。
数量限定
数量限定除了*,还有+加号,?问号,.点号,如果在一个模式中不加数量限定符则表示出现一次且仅出现一次:
+ 表示前面的字符必须出现至少一次(1次或多次),例如,”goo+gle”,可以匹配”gooogle”,”goooogle”等;
? 表示前面的字符最多出现一次(0次或1次),例如,”colou?r”,可以匹配”color”或者”colour”;
* 星号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次),例如,”0*42”可以匹配”42”、”042”、”0042”、”00042”等。
. 匹配除“\n”之外的任何单个字符。例如,“0.42”可以匹配”0i42”、”0w42”、”0142”等。
范围和优先级
()圆括号可以用来定义模式字符串的范围和优先级,这可以简单的理解为是否将括号内的模式串作为一个整体。例如,”gr(a|e)y”等价于”gray|grey”,(这里体现了优先级,竖直分隔符用于选择a或者e而不是gra和ey),”(grand)?father”匹配father和grandfather(这里体验了范围,?将圆括号内容作为一个整体匹配)。
语法(部分)
正则表达式有多种不同的风格,下面列举一些常用的作为PCRE子集的适用于perl和python编程语言及grep或egrep的正则表达式匹配规则
PCRE(Perl Compatible Regular Expressions中文含义:perl语言兼容正则表达式)是一个用C语言编写的正则表达式函数库,由菲利普.海泽(Philip Hazel)编写。PCRE是一个轻量级的函数库,比Boost之类的正则表达式库小得多。PCRE十分易用,同时功能也很强大,性能超过了POSIX正则表达式库和一些经典的正则表达式库。
| 字符 | 描述 |
|---|---|
\ |
将下一个字符标记为一个特殊字符、或一个原义字符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。序列“\”匹配“\”而“(”则匹配“(”。 |
^ |
匹配输入字符串的开始位置。 |
$ |
匹配输入字符串的结束位置。 |
\< |
表示词首。 例如\<abc表示以abc为首的词。 |
\> |
表示词尾。 例如abc\>表示以abc结尾的词。 |
{n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
{n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
{n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
* |
匹配前面的子表达式零次或多次。例如,zo*能匹配“z”、“zo”以及“zoo”。*等价于{0,}。 |
+ |
匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。 |
? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
. |
匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“(.|\n)”的模式。 |
(pattern) |
匹配pattern并获取这一匹配的子字符串。该子字符串用于向后引用。要匹配圆括号字符,请使用“(”或“)”。 |
x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
[xyz] |
字符集合(character class)。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。其中特殊字符仅有反斜线\保持特殊含义,用于转义字符。其它特殊字符如星号、加号、各种括号等均作为普通字符。脱字符^如果出现在首位则表示负值字符集合;如果出现在字符串中间就仅作为普通字符。连字符 - 如果出现在字符串中间表示字符范围描述;如果如果出现在首位则仅作为普通字符。 |
[^xyz] |
排除型(negate)字符集合。匹配未列出的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
[a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
[^a-z] |
排除型的字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
\w |
匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。 |
\W |
匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]’。 |
\s |
匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
\S |
匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
\d |
匹配一个数字字符。等价于 [0-9]。 |
\D |
匹配一个非数字字符。等价于 [^0-9]。 |
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配”never” 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
\B |
匹配非单词边界。’er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
优先级
优先级为从上到下从左到右,依次降低:
| 运算符 | 说明 |
|---|---|
\ |
转义符 |
(), (?:), (?=), [] |
括号和中括号 |
*、+、?、{n}、{n,}、{n,m} |
限定符 |
^、$、\任何元字符 |
定位点和序列 |
| |
选择 |
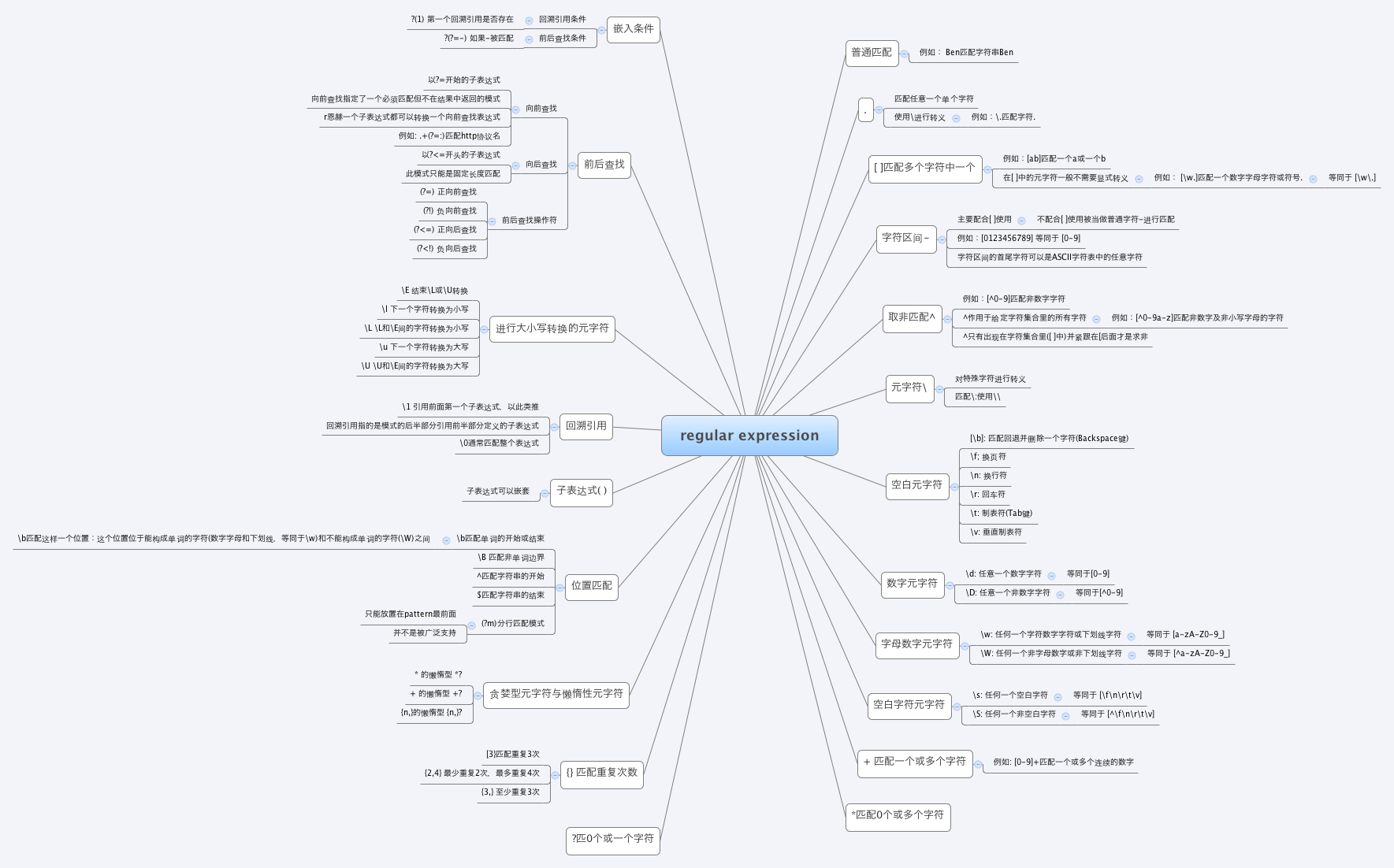
正则表达式思维导图